Text Classification
Objective
The following is a guide on finetuning a model for Text Classification tasks on Emissary, specifically focusing on Llama3-8B-Chat and BERT models that we recommend for such tasks.
Finetuning Preparation
Please refer to the in-depth guide on Finetuning on Emissary here - Quickstart Guide.
Create Model Service
Navigate to Dashboard, arriving at Model Services, the default page on the Emissary platform.
- Click + NEW SERVICE in the dashboard.
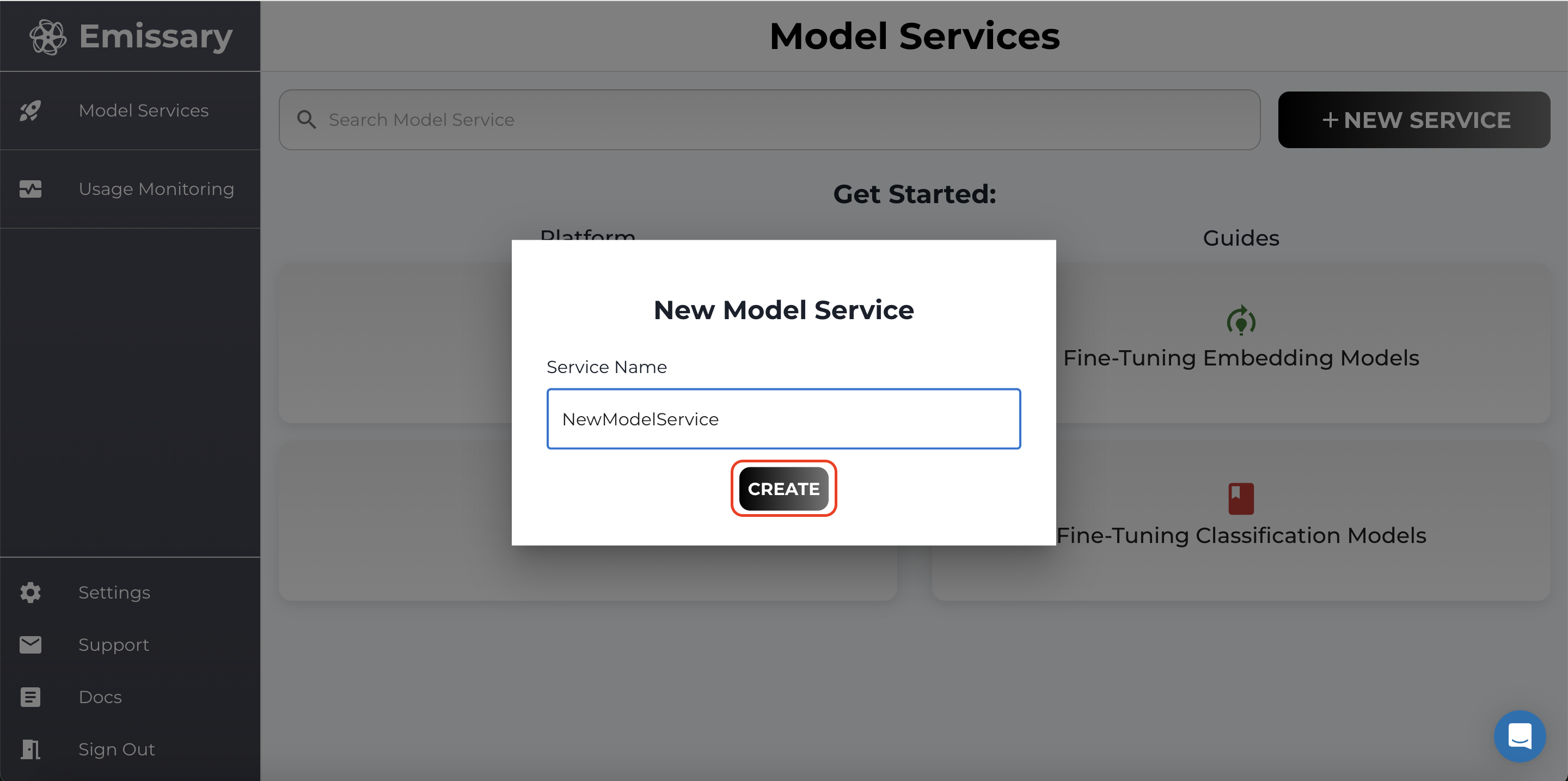
- In the pop-up, enter a new model service name, and click CREATE.
Uploading Datasets
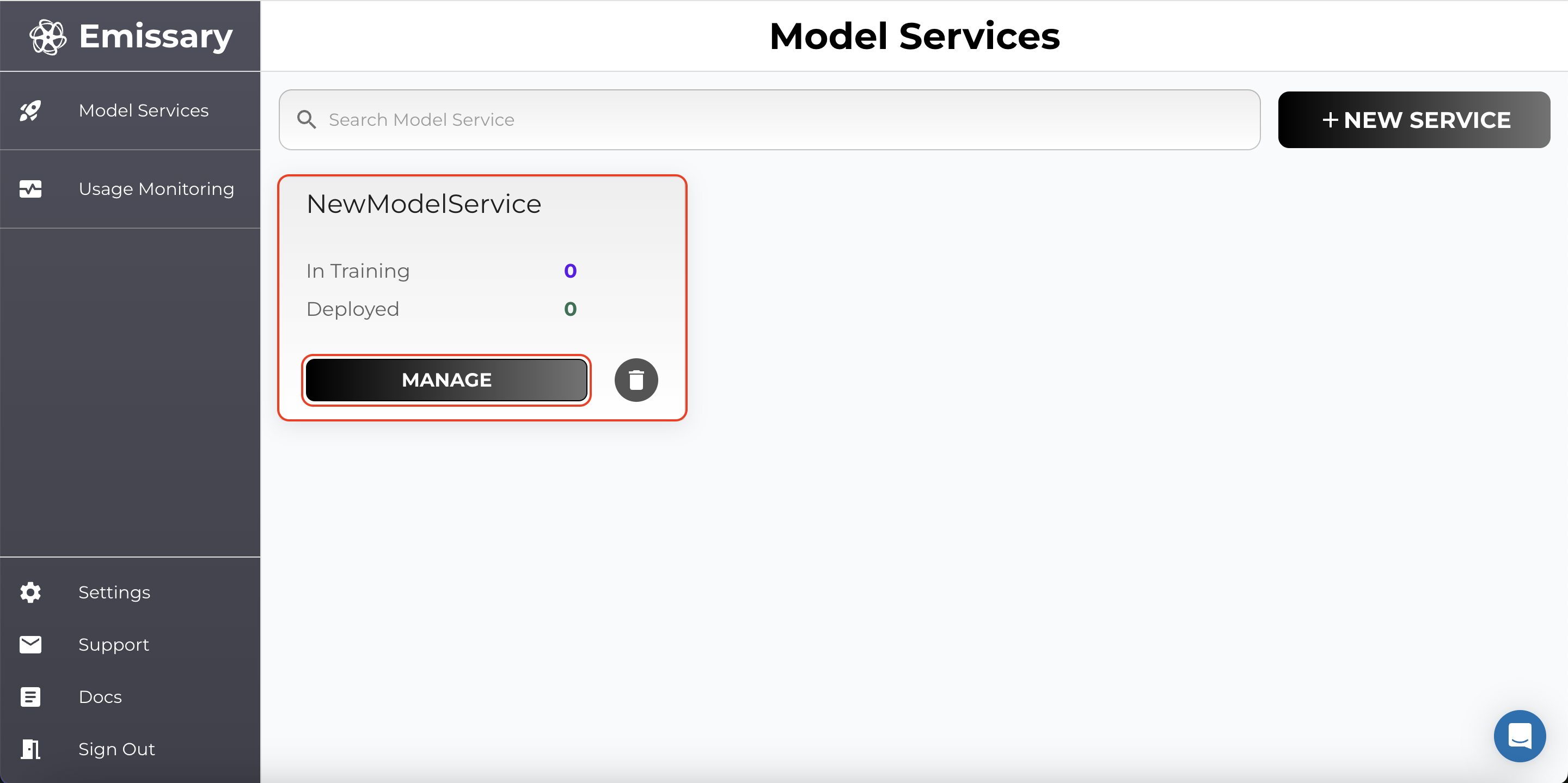
A tile is created for your task. Click Manage to enter the task workspace.
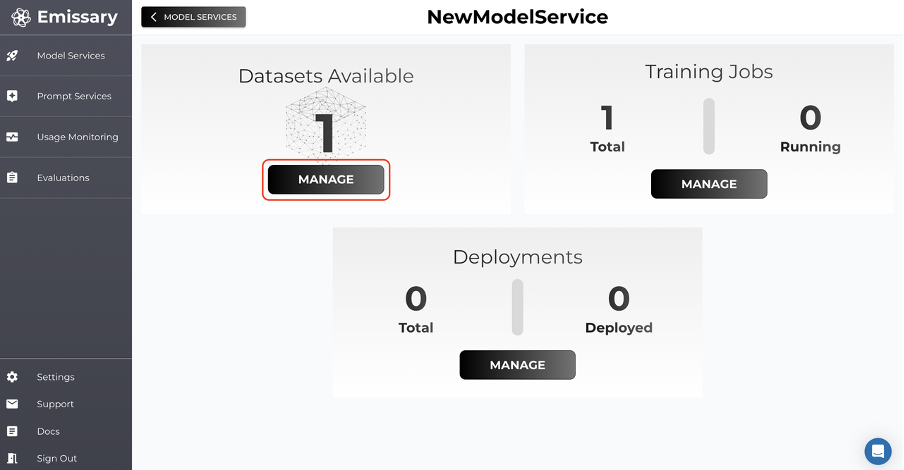
- Click MANAGE in the Datasets Available tile.
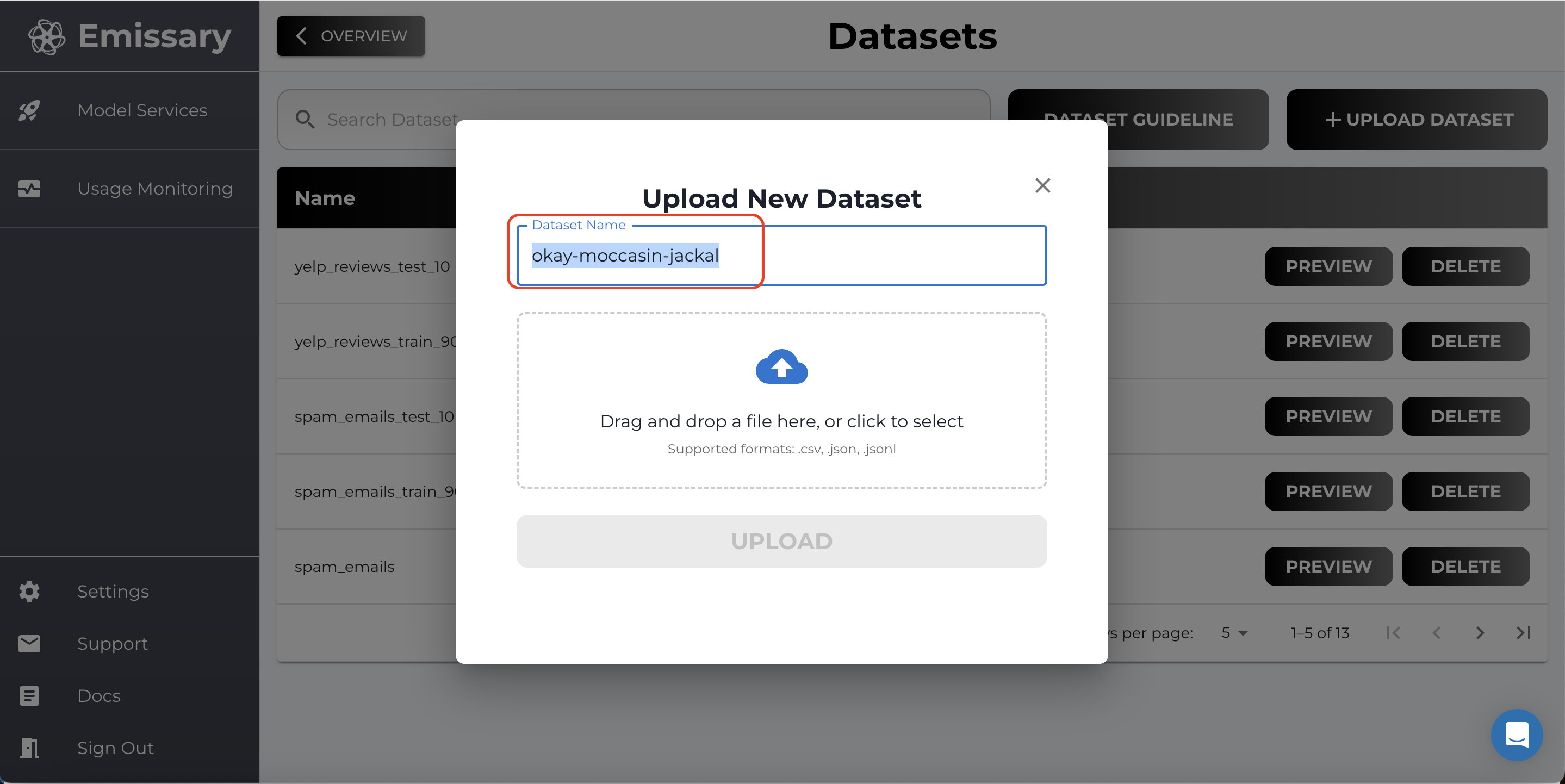
- Click on + UPLOAD DATASET and select training and test datasets.
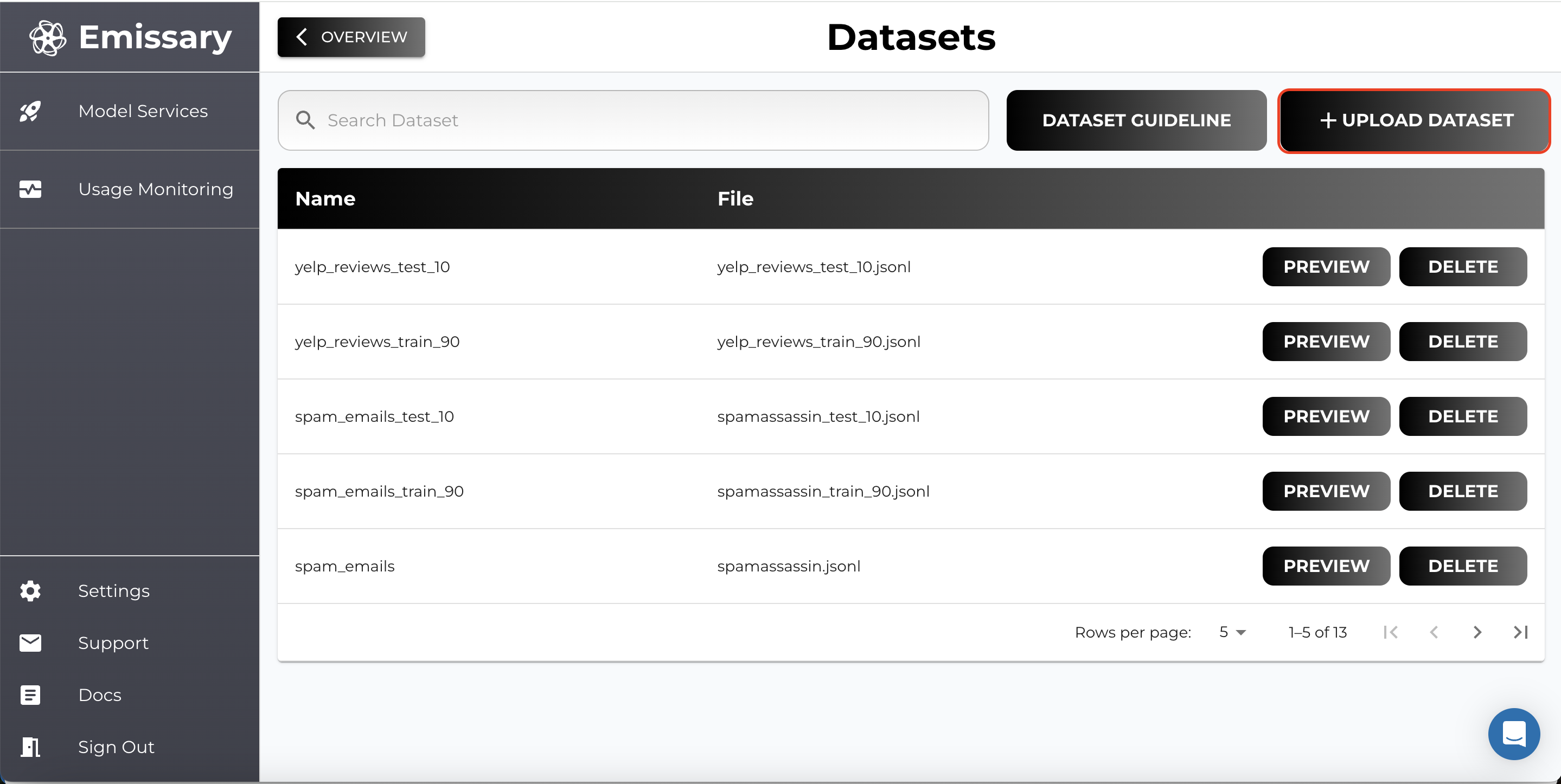
- Name datasets clearly to distinguish between training and test data (e.g., train_big_news_csv, test_big_news_csv, train_big_news_completion, test_big_news_completion).
Important Note: For BERT models or other traditional models, please use CSV (.csv) format.
Model Finetuning
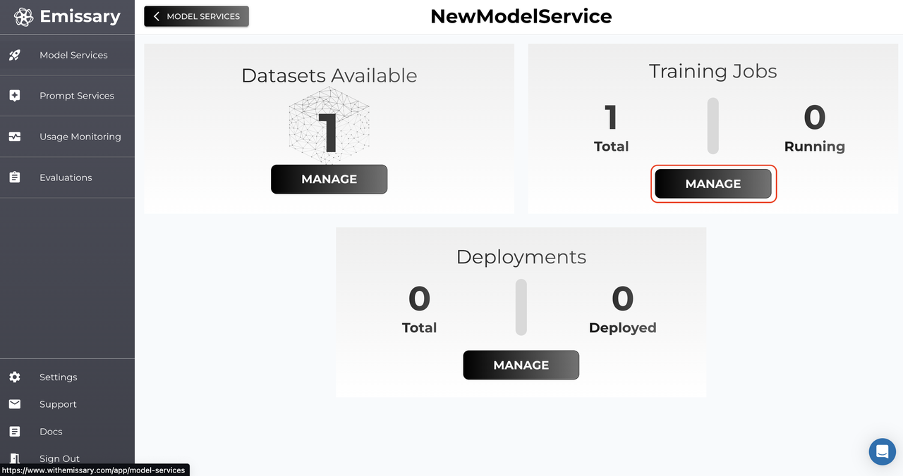
Now, go back one panel by clicking OVERVIEW and then click MANAGE in the Training Jobs tile.
Here, we’ll kick off finetuning. The shortest path to finetuning a model is by clicking +NEW TRAINING JOB, naming the output model, picking a backbone (base model), selecting the training dataset (you must have uploaded it in the step before), and finally hitting START NEW TRAINING JOB.
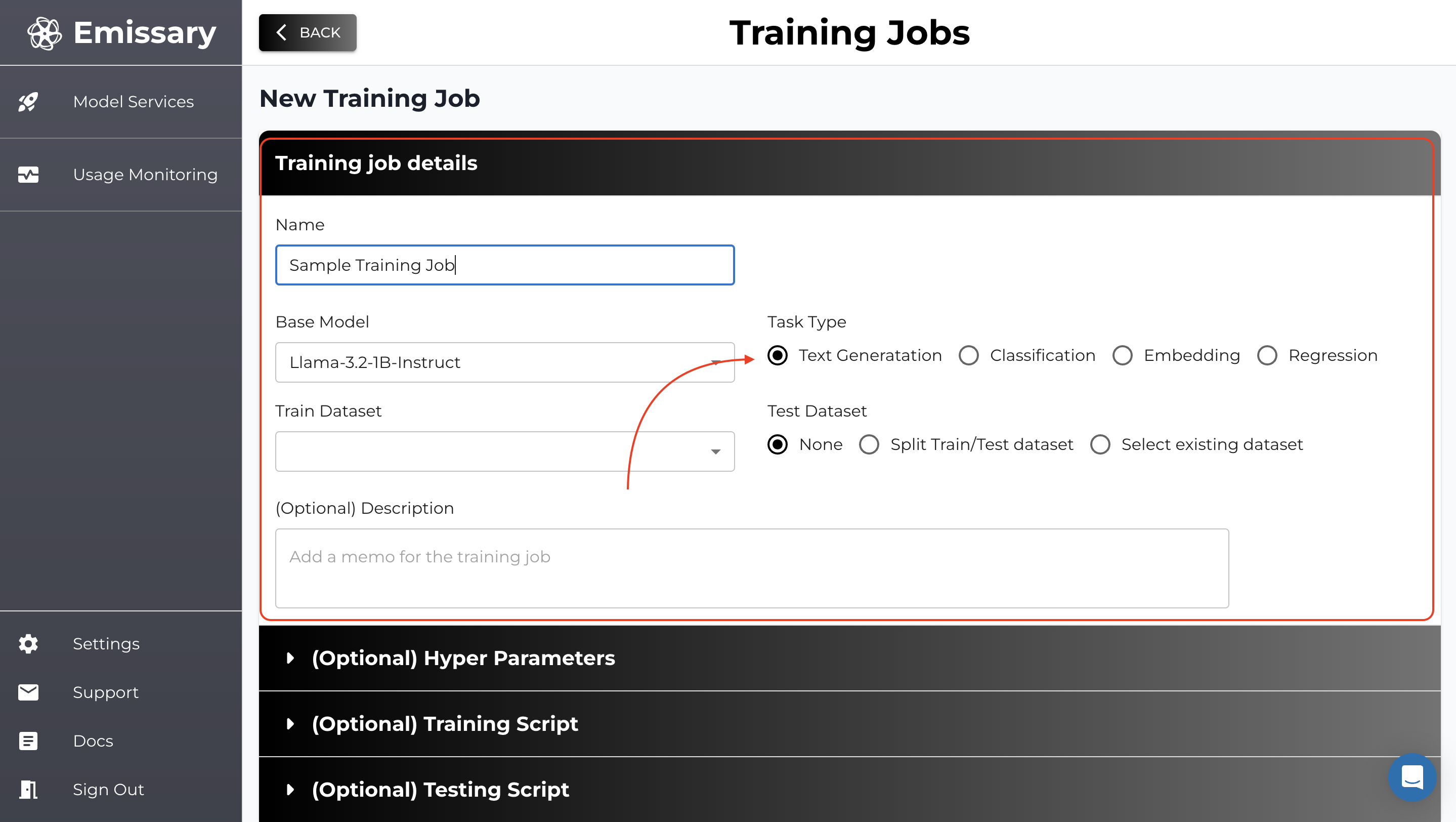
Selecting Base Model
-
BERT Model (for CSV datasets):
BERT is highly efficient for text classification with structured CSV data, especially for tasks where the primary focus is accuracy over natural language generation.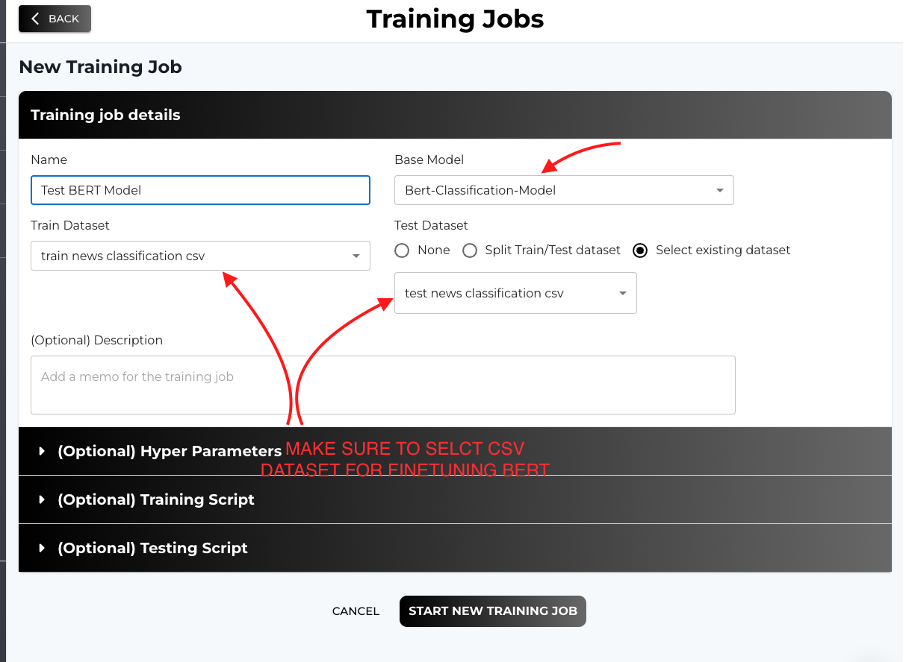
-
Llama 3 8B Model (for JSONL datasets):
The Llama model is well-suited for classification tasks that require deeper natural language understanding. JSONL is recommended for LLM models due to its flexibility with longer text inputs.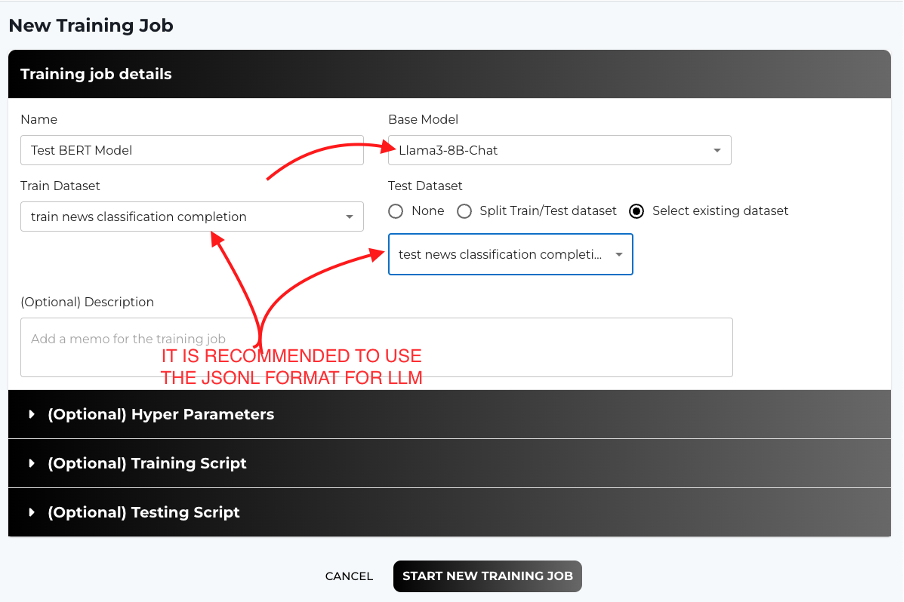
-
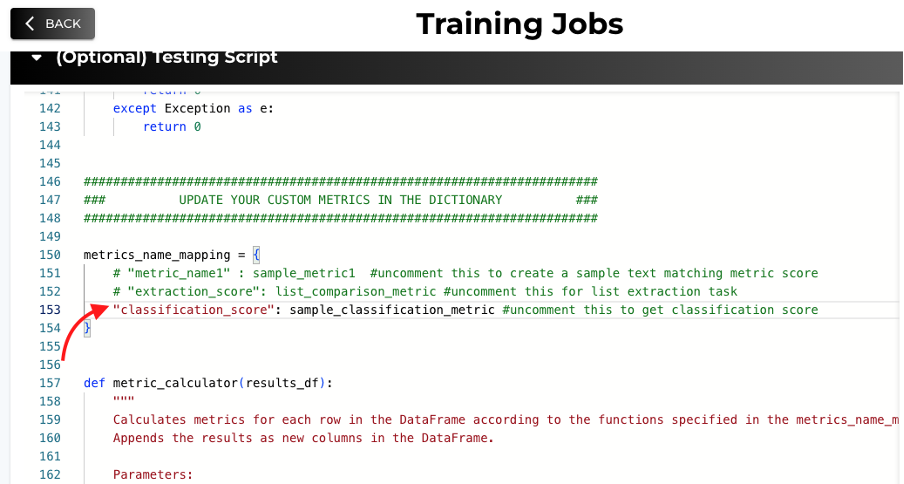
A custom function that compares two strings and gives a matching score has been provided. Uncomment "classification_score" to use.
Training Parameter Configuration
Please refer to the in-depth guide on configuring training parameters here - Finetuning Parameter Guide.
Model Monitoring & Evaluation
Using Test Datasets
Including a test dataset allows you to evaluate the model's performance during training.
- Per Epoch Evaluation: The platform evaluates the model at each epoch using the test dataset.
- Metrics and Outputs: View evaluation metrics and generated outputs for test samples.
- Post completion of training, check scores in Training Job --> Artifacts.
For the LLM model, expect the following:
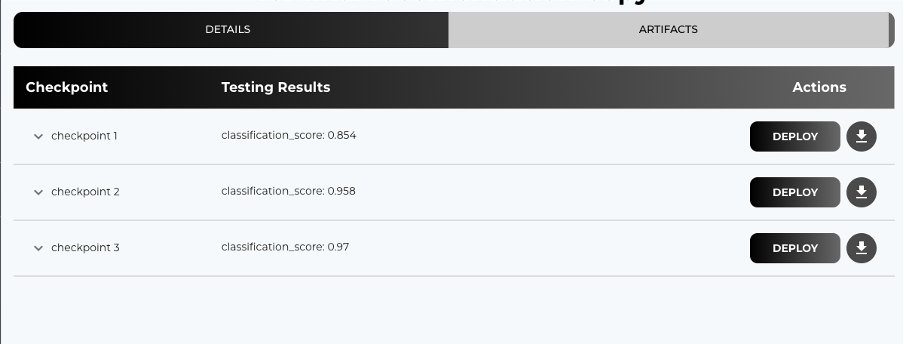
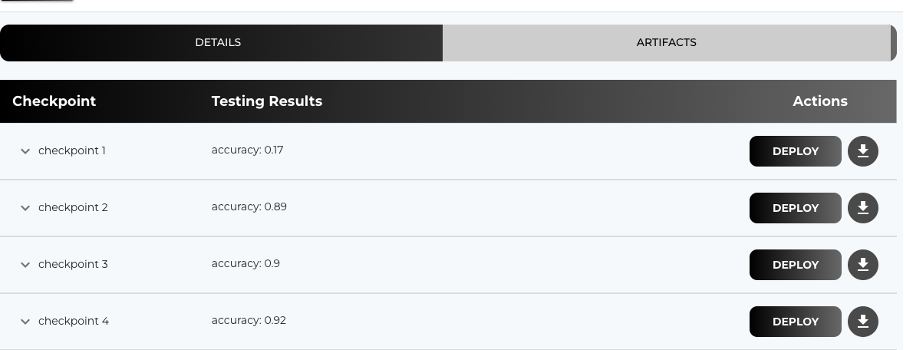
For BERT, expect accuracy scores as follows:
Evaluation Metric Interpretation
- Accuracy: Indicates the percentage of correct predictions.
- F1 Score: Balances precision and recall; useful for imbalanced datasets.
- Custom Metrics: Define custom metrics in the testing script to suit your evaluation needs.
Deployment
Refer to the in-depth walkthrough on deploying a model on Emissary here - Deployment Guide.
Deploying your models allows you to serve them and integrate them into your applications.
Finetuned Model Deployment
- Navigate to the Training Jobs Page. From the list of the finetuning jobs, select the one you want to deploy.

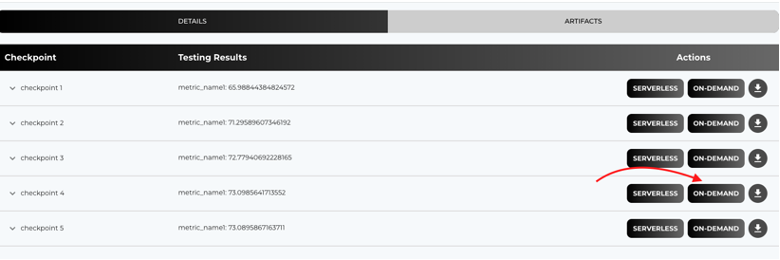
- Go to the ARTIFACTS tab.
- Select a Checkpoint to Deploy.
Parameter Recalibration
Adjust parameters like do_sample, temperature, max_new_tokens , etc. to finetune the model's response behavior.
- do_sample: Enable sampling for more varied outputs.
- temperature: Increase for more creativity, decrease for more deterministic responses.
- max_new_tokens: Limit the length of generated responses.
- top_p and top_k: Control the diversity of the output.
Best Practices
- Start Small: Begin with a smaller dataset to validate your setup.
- Monitor Training: Keep an eye on training logs and metrics.
- Iterative Testing: Use the test dataset to iteratively improve your model.
- Data Format: Use the recommended data formats for your chosen model to ensure compatibility and optimal performance.