Deployment Guide
Deployment Guide
Deploying your models allows you to serve them and integrate them into your applications. This guide walks you through the steps to deploy both base models and fine-tuned models, and explains the deployment parameters you can configure.
Deployment Options
There are two ways to deploy models on our platform:
- Base Model Deployment: Deploy pre-trained models without any fine-tuning.
- Fine-Tuned Model Deployment: Deploy models you've fine-tuned, selecting from various checkpoints based on performance metrics.
Deploying a Base Model
Step 1: Navigate to the Deployments Page
From your model service workspace, click on the Deployments tab to access the deployments page.
Step 2: Create a New Deployment
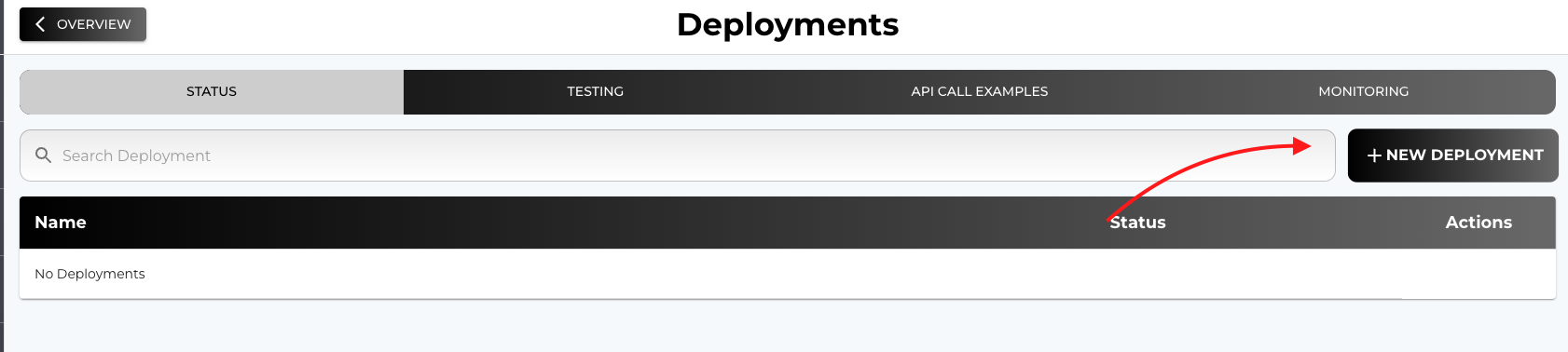
Click on the + NEW DEPLOYMENT button to start the deployment process.
Step 3: Choose a Base Model to Deploy
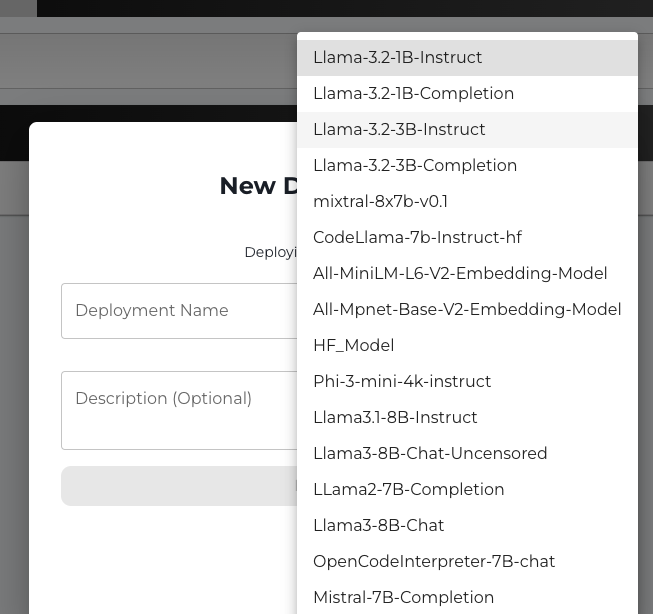
In the deployment creation form, select Base Model from the options. A list of available base models will be displayed.
Deploying a Fine-Tuned Model
Step 1: Navigate to the Training Jobs Page
From the list of the fine tuning jobs, select the one you want to deploy

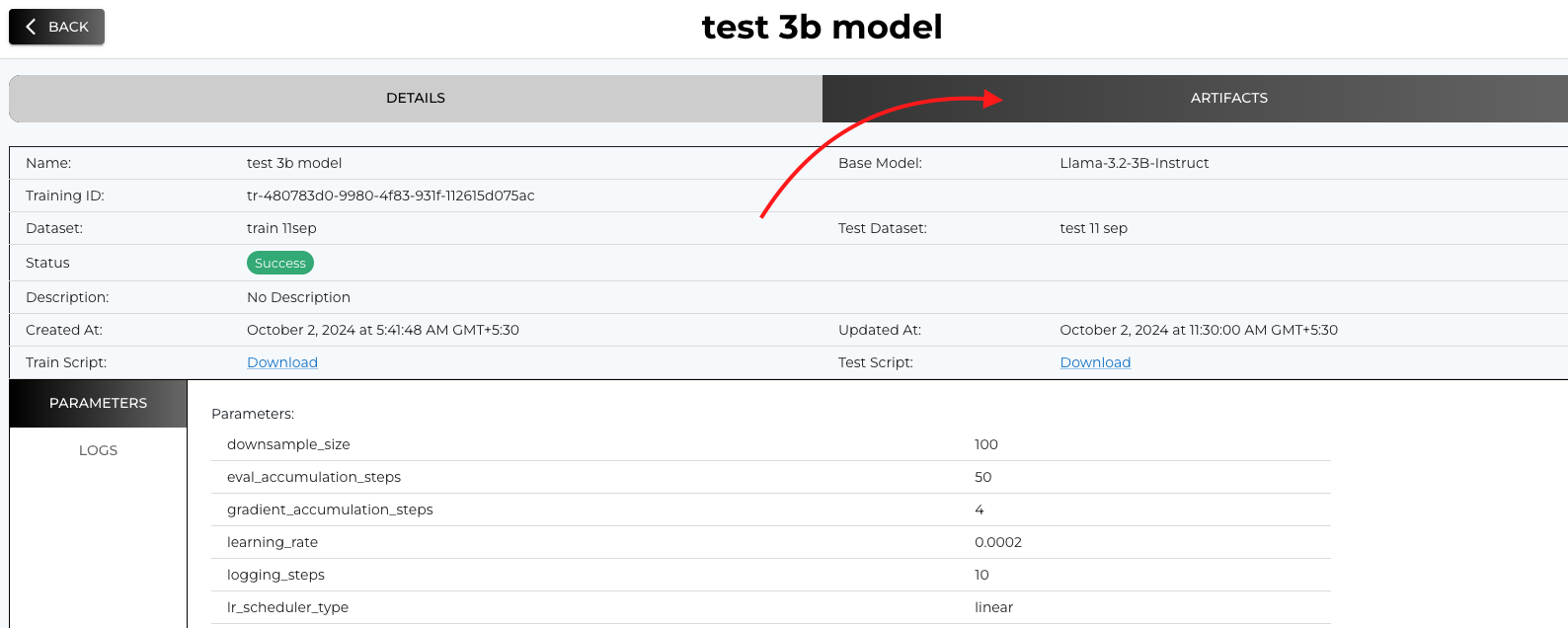
Step 2: Go the ARTIFACTS tab
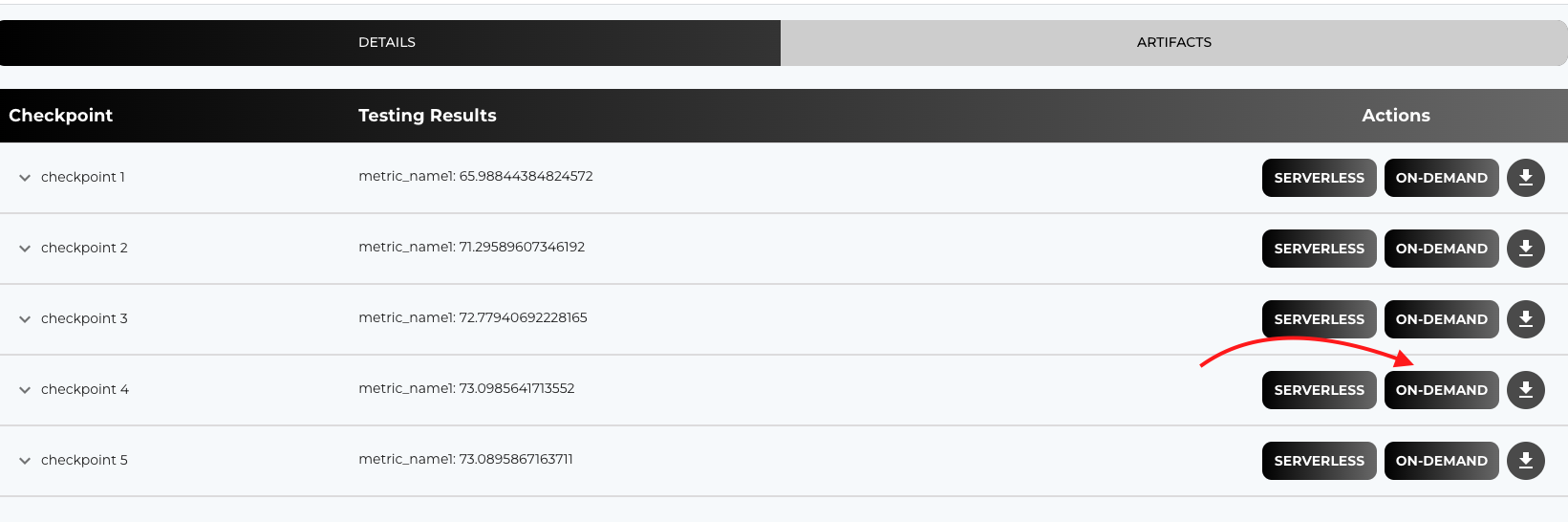
Step 3: Select a Checkpoint
For each training job, multiple checkpoints (corresponding to different epochs) are available. Each checkpoint shows its accuracy or performance metric (these are the same accuracies that you added in the testing script during training job creation).
- Review Checkpoints: Examine the list of checkpoints and their accuracies.
- Select Best Checkpoint: Choose the checkpoint that best suits your use case.
Testing Your Deployed Model
Once deployed, you can test your model directly from the platform to ensure it's working as expected.
- Navigate to the Testing Tab: Go to the Testing tab within your deployment.
- Select Your Deployed Model: Choose the model you just deployed from the dropdown menu if it's not already selected.
- Enter Input Text: Provide an input prompt or text in the input field.
- Generate Output: Click Generate to see the model's response.

Deployment Parameters
When deploying a model, you can configure various parameters to control how the model generates responses.
Available Parameters:
-
do_sample: (Boolean) Enables or disables sampling during text generation. -
true: The model will sample from the probability distribution, introducing randomness. -
false: The model uses greedy decoding, selecting the highest probability tokens (more deterministic output). -
temperature: (Float, between 0 and 1) Controls the randomness of sampling. -
Lower values (e.g.,
0.1): Model is more conservative and outputs are more deterministic. -
Higher values (e.g.,
0.9): Model outputs are more diverse and creative. -
top_k: (Integer) Limits the sampling to the topktokens with the highest probabilities. -
Example:
top_k = 50means the model will consider the top 50 tokens at each step. -
top_p: (Float, between 0 and 1) Implements nucleus sampling by limiting the cumulative probability top. -
Example:
top_p = 0.9means the model considers tokens that comprise the top 90% of the probability mass. -
max_new_tokens: (Integer) The maximum number of tokens to generate in the response. -
Example:
max_new_tokens = 128limits the response to 128 tokens. -
no_repeat_ngram_size: (Integer) Prevents the model from repeating n-grams of the specified size. -
Example:
no_repeat_ngram_size = 2prevents the repetition of any 2-word sequences.
Parameter Explanations
-
Sampling Parameters (
do_sample,temperature,top_k,top_p): -
Adjust these to control the randomness and creativity of the model's output.
-
Higher randomness: Use higher
temperature, enabledo_sample, and set highertop_kortop_p. -
More deterministic output: Disable
do_sample, lowertemperature, and settop_kortop_pto lower values. -
Length Parameters (
max_new_tokens): -
Control the length of the generated output.
-
Useful to prevent the model from producing excessively long responses.
-
Repetition Penalty (
no_repeat_ngram_size): -
Helps to avoid repetitive phrases in the generated text.
-
Setting this parameter encourages the model to produce more varied language.
Monitoring and Managing Deployments
After deploying your model, you can monitor its performance and manage it as needed.
Deployment Status
- Check Status: View the status of your deployments (e.g., Running, Pending, Error) in the Deployments STATUS tab.
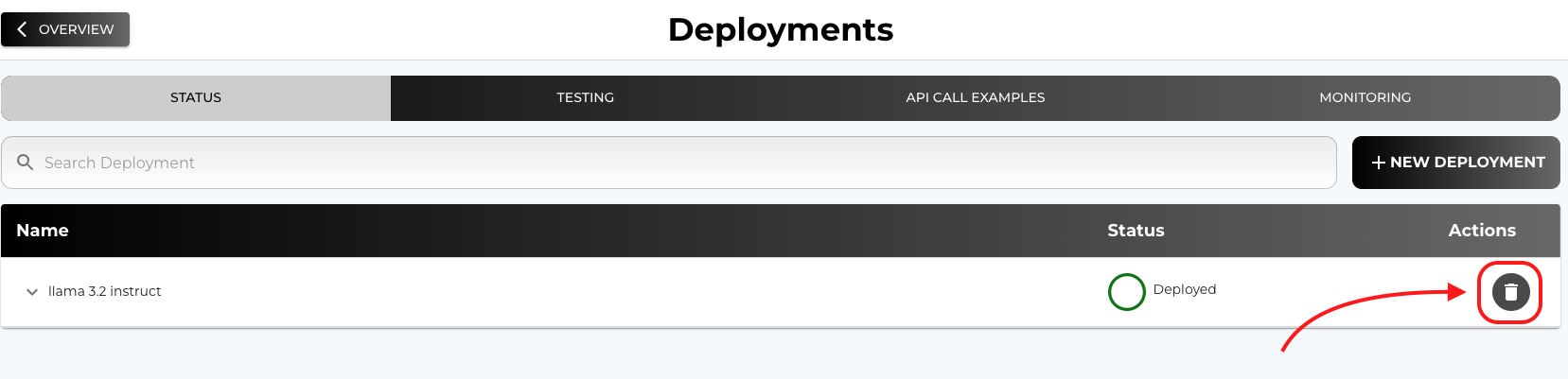
Deleting a Deployment
- Remove Unused Deployments: If a deployment is no longer needed, you can delete it from the Deployments STATUS tab.
- How to Delete: In the Deployments tab, select the deployment you wish to remove and click on the Delete button.
Best Practices for Deployment
- Choose the Best Checkpoint: For fine-tuned models, select the checkpoint with the best performance metrics for your use case.
- Start with Default Parameters: Begin with default deployment parameters and adjust based on the output and performance.
- Test Thoroughly: Use the testing tab to try various inputs and ensure the model behaves as expected.
- Monitor Usage: Keep an eye on the model's performance and resource usage to optimize efficiency.
- Handle Errors Gracefully: Implement error handling in your application to manage any issues with the deployed model.
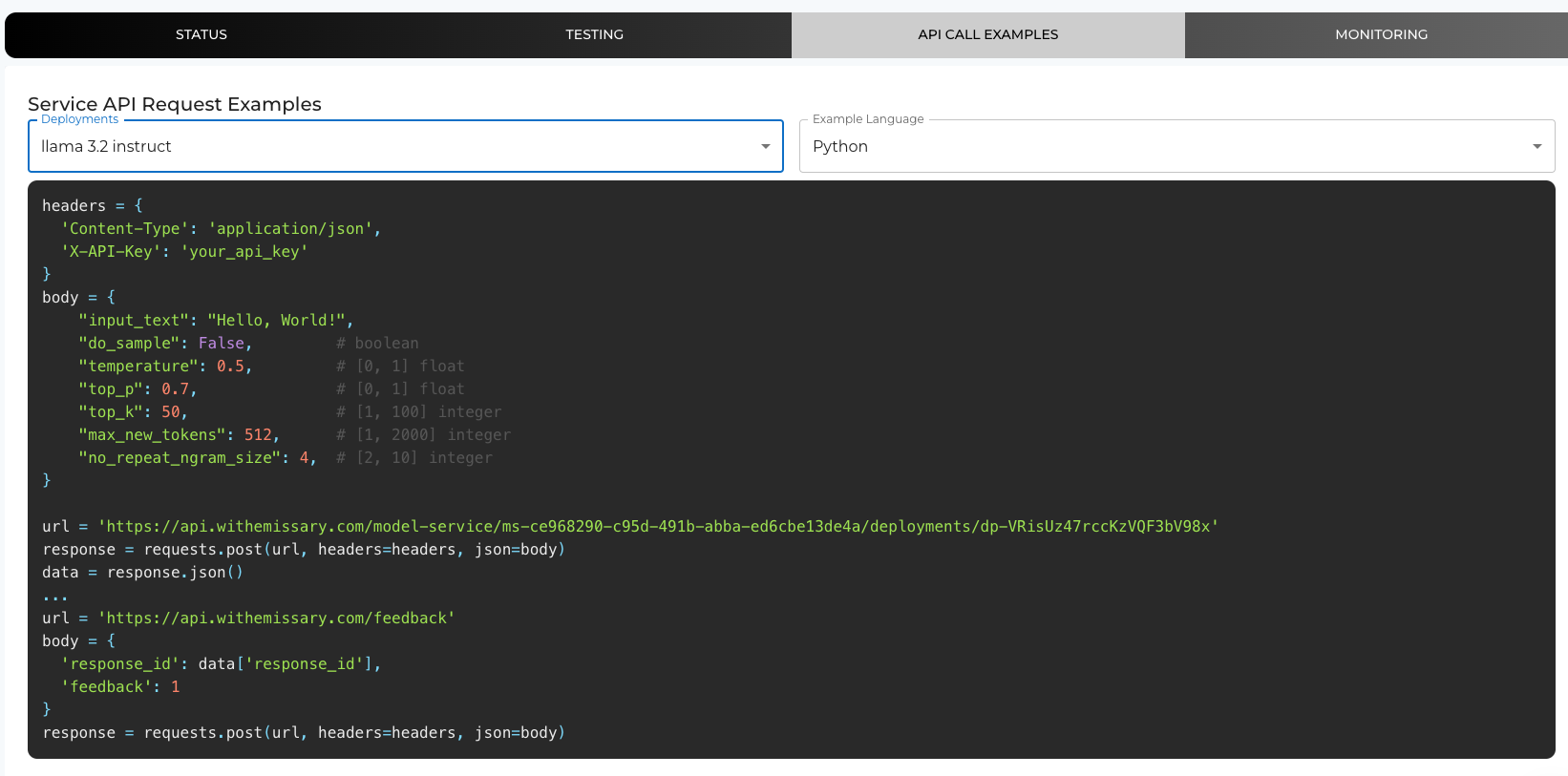
Integrating the Deployed Model into Your Application
- API Endpoints: Use the provided API endpoints to integrate the model into your software.
- Authentication: Secure your API calls with the necessary authentication tokens or API keys.
- Code Examples: Refer to the API Call Examples section in the platform for sample code snippets in various programming languages.
By following these steps and guidelines, you can successfully deploy both base models and fine-tuned models, selecting the best-suited version for your application. Adjust the deployment parameters to optimize the model's performance according to your specific needs.